

In this bash tutorial, you will get the program about how to count word frequency in bash script. This is done by using for loop, tr command and command substitution in linux.
This program has checked the following conditions listed below
Conditions:
- Duplicate words won’t be repeated
- Input should be taken from command line
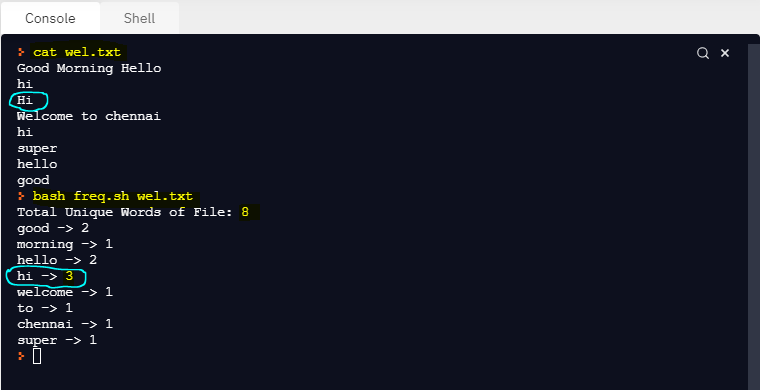
- Uppercase and lowercase words should be treated as equal.
SOURCE CODE
(freq.sh)
# set the new name for given command line input
newname="input.txt"
# convert the given file from cmd into lowercase letters and save them into new file
tr A-Z a-z < $1 > $newname
# get the input file collection after the upper-lower conversion
fp=`cat $newname`
# create an empty array
db=()
# set the boolean flag to false
f=false
# define the counter variable
k=0
# loop the file word by word
for w in $fp
do
# if the array is an empty add the first word of file to array
if [ ${#db[*]} == 0 ]
then
db[$k]=$w
k=$(($k+1))
# if array is non empty then add the words of file to array using boolean flag
else
for i in ${db[*]}
do
if [ $w = $i ]
then
f=true
break
else
f=false
fi
done
if [ $f = false ]
then
db[$k]=$w
k=$(($k+1))
fi
fi
done
# display the count the word frequency
echo "Total Unique Words of File: ${#db[*]}"
for k in ${db[*]}
do
rs=`grep -c $k $newname`
echo "$k -> $rs"
done
OUTPUT
RELATED POSTS
1. Arrays in Bash Script
2. Strings in Bash Script
3. Switch Case in Bash Script
4. Command Line Arguments
5. For Loop in Shell Script
6. Operators in Bash Script
MORE TUTORIALS